This article is for users, who are familiar with Kubernetes cluster, its basic principles and Kafka and solves a specific data persistence problem related to running a "Confluent Platform" in Kubernetes cluster. It took me several hours to study the priciples and come up with this solution which works great. It will hopefully help other users having the same use case.
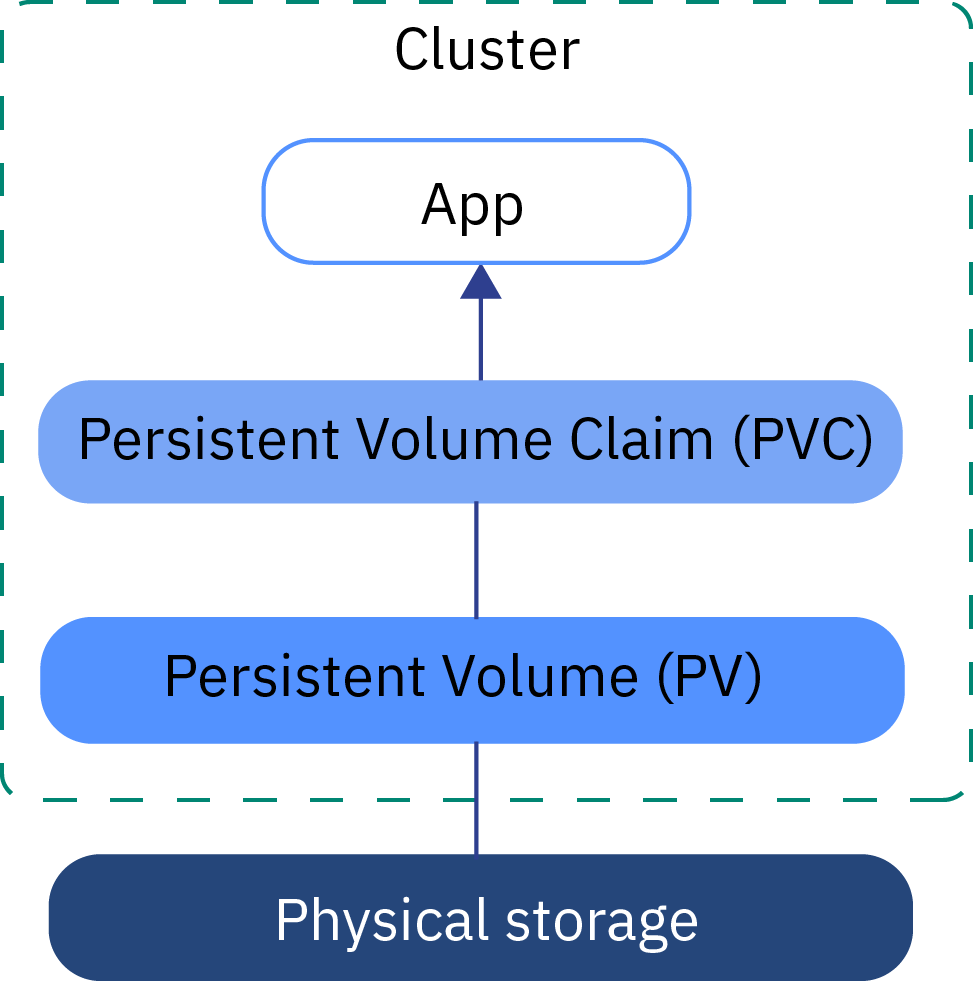
Image Source: https://cloud.ibm.com/docs/openshift?topic=openshift-kube_concepts&locale=en
Solving persistence for your Kafka cluster when using Confluent Platform
What is Confluent Platform?
If you wanted to set up Kafka on Kubernetes cluster together with ksqlDB, you must have found a neat helm chart, which eases the deployment of this platform on your Kubernetes cluster from Confluent Platform.
This is the URL of the Confluent Platform helm chart:
By default, it starts 3 instances of Kafka, Zookeeper, ksql server, Kafka REST endpoints, Kafka connect and Schema Registry. You can use it right away and it's pre-configured the way that they all see each other and act as one platform.
Problem: how to setup persistence?
When you uninstall the helm chart and pods don't exist anymore, data which were stored in Kafka instances are gone. To prevent that, you should set in values.yaml:
persistence:
enabled: trueThis would create a persistence volume claims (PVC), which would lookup a persistence volumes (PV) and bind them
But, you would probably end up with something like this:

There are several persistent volume claims (PVC), but are unable to find the corresponding persistent volume (PV)
Let's create the persistent volumes
storageClassName: local-storage
What is that? for Kafka, you should not use NFS (network file system) to use as persistent volume. Why? Because it's sooo slow. What's the answer then?
Local persistent volume!
First, you should create storage class and name it e.g. local-storage. Storage class can determine the "quality" of the service, or how fast such storage is. For example, you can have big, but slow storage, which you'd only use for backups, or fast and smaller SSD. This is what's StorageClass about. Let's name ours just "local-storage".
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumerIn case of creating local storage, you need to set
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumerThen, check out these lines:
local:
path: /mnt/data/datadir-0-cp-helm-charts-cp-kafka-0
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- pcOh yeah, Kubernetes allows you to use directory on node and use it as storage. Why is it so cool? because such local storage is usually very FAST. Ideal for Kafka with so many data operations.
pc in this case is the node where this mount directory exists.
Why is it needed? because pods can run on any nodes of your cluster. This is why we need to specify on which exact node is this directory present.
Reference to official documentation https://kubernetes.io/docs/concepts/storage/volumes/#local
Great, we can create such fast local volumes and use them right away!
Not so fast.. Another problem is, that confluent kafka platform by default spawns...
]]>