Hadoop tutorial
First, before beginning this Hadoop Tutorial, let's explain some terms.
What is Big Data?
Big Data is the reality of to do business for most organizations. Big data is a collection of large data sets which can not be processed using routine data processing techniques. Big Data is no longer a given, it became a complete subject which involves various tools, techniques and frameworks. Big data involves data produced by applications and devices. Some areas that are under the Big Data roof
Some examples of Big Data
Social Media data such as Facebook and Twitter capture information and views displayed by millions of people worldwide. Currency Exchange data contains information on the "buy" decisions and "sell" on the one hand made from different companies by clients. Power Grid data contains information used by a particular node with respect to a base station. Transport Data includes model, capacity, availability and distance of a vehicle. Search Engine Data recover much data from different databases.
Big Data types
The data will be of three types:
- structured data is relational data.
- semi-structured data are XML data.
- unstructured data are documents like Word, PDF, Text, Media Newspapers
Technologies used in Big Data
There are various technologies in the market from different vendors, including Amazon, IBM, Microsoft, etc. to manage large volumes of data. In this article we will examine the two following classes of technologies:
Operational Big Data
It includes a system like MongoDB operational capabilities that provide real-time, interactive workloads where data is mainly captured and stores. NoSQL big data systems are designed to take advantage of new architectures of cloud, it makes operational workloads of large data much more manageable, cheaper and faster to implement.
Big Data Analytics
It includes systems such as Massively Parallel Processing (MPP) systems and database MapReduce analytic capabilities that provide complex analysis to show which can affect most or all of the data. MapReduce provide a new method of data analysis that is corresponding to the capabilities of SQL and MapReduce-based system that can be scaled from single servers to thousands of high-end devices and low.
Difficulties encountered by Big Data
The main challenges related to large volumes of data are:
- Data Capture
- Conservation
- Storage
- Research
- Share
- Transfer
- Analysis
- Presentation
Hadoop Big Data Solution
Old traditional approach
In traditional business old approach will have a computer to store and process large data. In these data will be stored in an RDBMS such as Oracle Database, MS SQL Server or DB2 and complicated software can be written to interact with the database process the required data and present users for purposes of analysis.
Limitation of the traditional approach
We use this approach where we have less volume of data that can be accommodated by the database servers or standard data to the processor limit that is currently processing the data. But when it comes to trade with huge amounts of data traditional approach is really a tedious task to process the data via a traditional database server.
The Google solution
MapReduce algorithm is Google's solution for this problem. In this algorithm, we split the task into smaller parts and assign the parts to many computers on the network and collect the results to form the final result dataset.
Where the Apache Hadoop fits in? Let's first begin in this Hadoop tutorial what the Apache Hadoop actually is. Hadoop is basically an open framework of software that can store data and process data through hardware clusters. Hadoop is designed to grow from a single server to thousands of machines offering to each local storage and computer. Hadoop gives a massive storage for any data type with enormous processing power and the ability to handle tasks or virtually unlimited parallel jobs.
Hadoop Big Data Solution and history Doug Cutting, Mike Cafarella and his team took the solution provided by Google and started an open source project called Hadoop. Hadoop in 2005 is a trademark of the Apache Software Foundation. Apache Hadoop is an open source framework written in Java that allows processing of large data sets on distributed computer clusters using simple programming models. Hadoop runs applications using the MapReduce algorithm, where the data are processed in parallel on various processor nodes. Hadoop framework is capable enough to develop applications that run on computer clusters and they could do a full statistical analysis to huge amounts of data.
Hadoop architecture framework
Hadoop Framework consists of four modules:
1) Common Hadoop 2) Hadoop Yarn 3) Hadoop Distributed File System 4) Hadoop MapReduce
Hadoop Tutorial
Discussing in detail the four hadoop modules
1) Common Hadoop is Java libraries and utilities required by other Hadoop modules. These libraries provide files and OS level abstractions system to contain the Java files and scripts needed to start Hadoop.
2) Yarn Hadoop is a framework for task scheduling and managing cluster resources.
3) Hadoop distributed file system that provides broadband access to the application data.
4) Hadoop MapReduce is Yarn based system for parallel processing of large data sets.
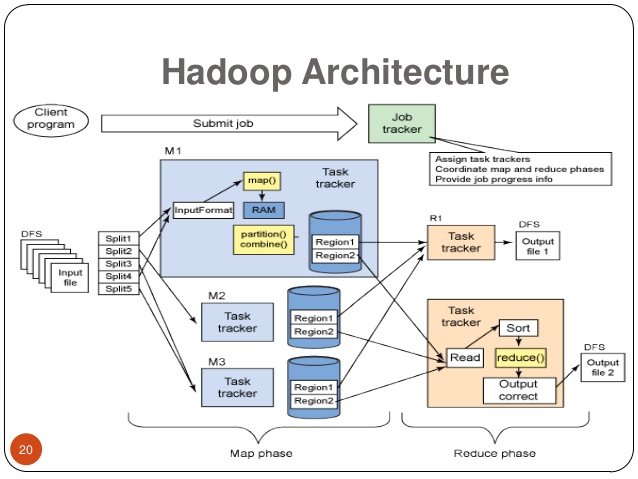
Working with Hadoop
There are 3 steps in Hadoop can discuss in detail in this Hadoop tutorial: 1st step: the user submits a job / Application to Hadoop for the necessary process by specifying the following:
-
Define the locations of the input and output files in the distributed file system.
-
Define the Java classes as a jar file containing the implementation of the plan and reduce functions.
-
Definition of the configuration of the job by defining different parameters specific to the job.
2nd Step: Hadoop (A Hadoop job client) then submits the job (jar / executable etc.) and configuring the Job Tracker which then assumes responsibility for distributing the software / configuration to the slaves, scheduling tasks and monitoring of granting status as diagnosis information to the job client. 3rd Step: Task Trackers on different nodes perform the task by the implementation and output of the function to reduce MapReduce is stored in the output files on the file system.
Hadoop Tutorial
Benefits of Hadoop
Top reasons to choose Hadoop is its ability to store and process huge amount of data quickly. Other benefits of Hadoop are:
• Computing power - Hadoop distributed computing data module quickly process any amount of data. The increase in processing power using several computing nodes. • Flexibility - information you should pretreatment before storing. You can store as much information as you require and choose how to use it later. • Fault Tolerance - Information and handling of the application are insured against hardware failures. Incase a node goes down task are automatically redirected to other nodes to ensure that distributed computing is not lacking. Hadoop automatically store multiple copies of data. • Low Cost - Hadoop is open source Hadoop software framework is free & used good material to store large amount of data. • Hadoop is scalable - With little administration, we can easily increase our system simply by adding new nodes.
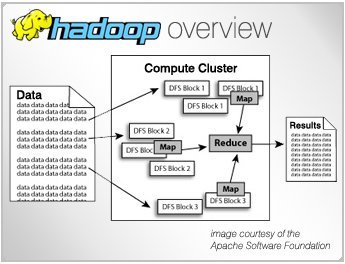
Hadoop MapReduce
It is a software framework for easily writing applications that process large amounts of data in parallel on large clusters working on thousands of basic hardware nodes reliably and fault tolerance.
The two different following tasks that programs perform MapReduce Hadoop actually refer the term:
1) Task Map: This is the first task that takes the input data and converts it into a data set, where individual elements are decomposed into tuples (key / value pairs).
2) Reduce Group: The reduction task is always executed after the task map. Out of a task card is taken as input and combines these data tuples in a small set of tuples.
Hadoop Tutorial
Author: Written by Mubeen Khalid for CodeGravity.com ®
Image Resources: http://www.bigdatatraining4all.com http://www-01.ibm.com/software/ebusiness/jstart/hadoop/ http://www.slideshare.net/bloodthirsty86/big-data-concepts http://www.oxyent.com/Big%20Data%20Hadoop%20based%20analytics.html http://analyticsdud.blogspot.com/2013/05/how-is-apache-hadoop-using-big-data.html
Author bio
 Matej Koval is a Full stack senior Java developer, Scrum master of a team.
Experienced in Debian Linux administration and technologies like: Spring Boot, Quarkus, Kafka, Docker, Kubernetes, Angular.
More info about me: LinkedIn
Matej Koval is a Full stack senior Java developer, Scrum master of a team.
Experienced in Debian Linux administration and technologies like: Spring Boot, Quarkus, Kafka, Docker, Kubernetes, Angular.
More info about me: LinkedIn